D-CAT 😼 - Decoupled Cross-Attention Knowledge Transfer between Sensor Modalities for Unimodal Inference
INFORMATION
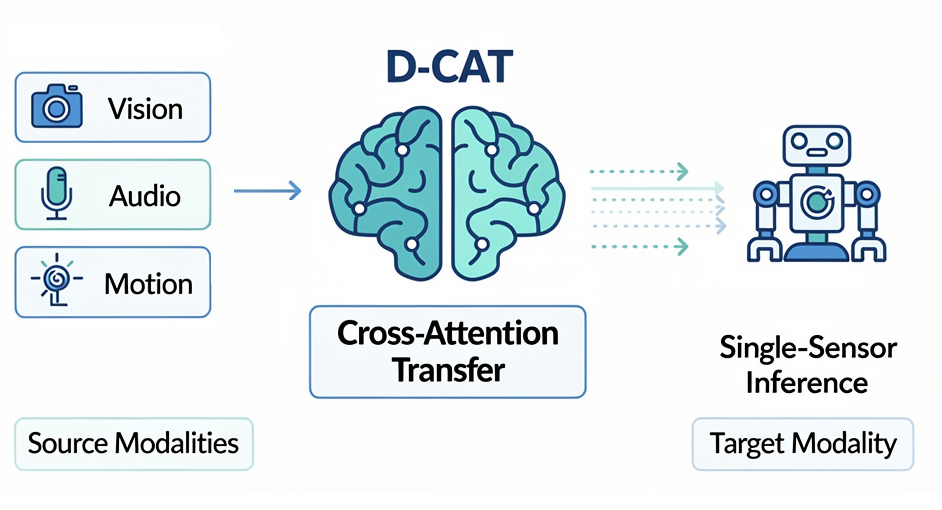
You’ve built a high-performing model using camera, audio, and IMU data, great! But when it’s time to deploy, your industrial partners hit a roadblock: scaling to 60,000 sensors isn’t feasible due to cost and complexity.
What if you could train with multimodal data but deploy with just one sensor, slashing costs and complexity without sacrificing performance?
Meet D-CAT: A framework for multimodal training with decoupled inference thanks to a novel cross-attention loss. Train robustly, deploy efficiently.
Method

Cross-attention relates the elements from two different sequences by using the query from one sequence and the key and value from the other sequence. However, cross-attention creates a strong dependency between modalities, where the two sensor data cannot be decoupled at inference.
The core aspect of D-CAT is a novel decoupled cross-attention loss. We aim to align:
With , , and the query, key, and value projections of the target modality embeddings, and , the key and value projections of the source modality embedding. Hence, our loss becomes (after factoring out ):
Since the cross-attention is only present in the loss but not in the network itself (as opposed to classic attention), the modality can be removed at inference!
For more mathematical proof of this work, check out the paper.
Results
Interestingly, we found that in in-distribution scenarios, D-CAT is effective at transferring knowledge from a high performing modality (e.g. images) to a sensor modality with lower accuracy (e.g. IMU) but not the other way around.
On the other hand, in out-of-distribution scenarios, D-CAT is instead influenced by whether the source model has overfitted on its dataset. We found that knowledge cannot be transferred from a model that has overfit on its training data.